Benchmarking of customized engines vs Google Translate and DeepL
Measurements of edit distance and BLEU scores
Evaluation by specialist linguists
Automated Metrics Supported
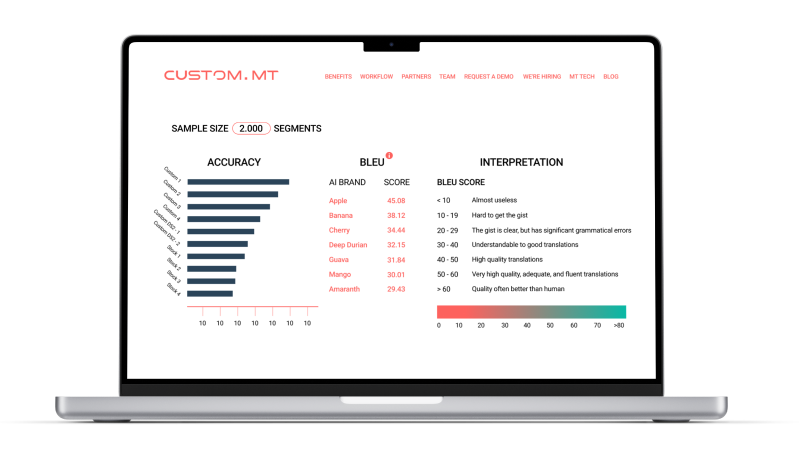
BLEU
hLEPOR
COMET
METOR
Human Evaluation Methods:
Segment Scoring by Expert Panel
Scoring covers a lot of ground quickly. It’s practical when comparing 5 or more different models at the same time.
Specialist linguists go segment by segment and score them from 1(Useless) to 5 (Perfect). The business analyst works with 3 reviewers on each evaluation and reconciles their scores to reduce subjectivity in judgement.
All tests are Blind tests, and linguists don’t know which specific technologies are being evaluated.
60 minutes per model
% of segments scored Perfect or Good without human corrections
An engineer prepares a test dataset of 100 segments per model. These segments are selected based on their metric scores to represent all models fairly.
Blind ABC Test
ABC test is useful to compare 2-3 models and find a clear winner among them.
The ABC test takes only minutes, not hours, and is easy to run. It does not provide an effort measurement, and it is not practical to use it to compare more than 4 models.
40-50 minutes total
% of segments preferred by linguists
Three specialist linguists pick the best translation from 2-3 options, If two or more linguists agree on the best output, that model scores a point. The test continues for 100 segments. The model with the highest score total wins.
Edit Distance Measurement
Intensive test to estimate the human effort needed to polish MT
Significantly more accurate than scoring but more labor intensive.
120 minutes per model
Word-error rate measurement
Three linguists edit a sample MT output and bring it to the required level of quality. An engineer runs a script to measure the percentage of words changed (word error rate) on the document and the segment level.
Error Classification
Intensive test to understand model performance in detail
Significantly more accurate than scoring but more labor intensive.
150 minutes per model
Weighted error score, error distribution
On top of editing a sample MT output, linguists flag and classify errors based on a pre-agreed typology. We rely on a streamlined DQF/MQM harmonized metric to measure accuracy, language fluency, style, locale convention, spacing issues and other errors. This approach allows the project leaders to have in-depth understanding of the cognitive effort required to edit the MT output.


")