Multilingual TMX Cleaner
Fully automated solution for cleaning translation memories and performing terminology checks to get more accurate translations.
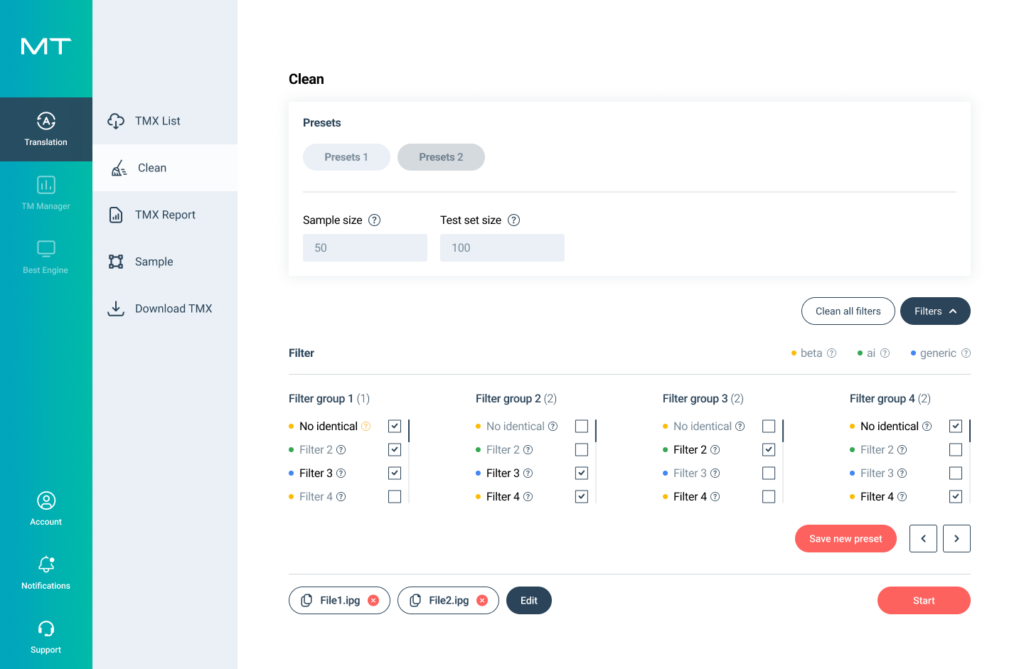
Better TMX leads to better machine translation quality when you train your custom models
WHY CLEAN YOUR TMX?
As translation memories accumulate over the years, they lose quality and get clogged with human errors and mistranslations. When used for training, datasets with repeated mistakes “teach” the machine translation model to use wrong translations instead of correct ones. Our solution automatically flags incorrect segments and removes or repairs them to give you clean data to work with.
25-45%
of incorrect segments are usually identified during a routine scan & remove check
30+
quality check filters
including neuron-based ones


EXPLORE THE BENEFITS
Multilingual
Upload translation memories containing multiple languages, and the software will automatically break them into language pairs.
Smart presets
Save your favorite filters to a preset and significantly speed up your cleaning process.
Neuron filters
Leverage AI-powered filters for text processing in many languages.
Fully customizable
Our filters are customizable and can be tailored to specific requirements.
More happy clients
Impress your clients and win new ones with a state-of-the-art automation tool.
Fully
automated
Custom.MT TMX Cleaner automatically flags segments that need to be removed or repaired. So your linguists can save hours of manual work.
Boost savings from translation memory with the power of AI
Remove false positives and segments with mistakes, and increase translation memory reuse in TMS by up to 6%. With our TMX Cleaner, you can do that in a fully automated way, using a combination of RegEX rules and neural network technology.
ADVANCED FILTERS
Empty source/target
Removes translation units with empty source or target.
Too long/short
Removes translation units with source or target containing more than 512 characters or less than 3 words.
Repeated words
Removes translation units containing consecutive repeated words in source or target.
Space noise
Removes translation units containing too many consecutive spaces in source or target.
Wrong language
Removes translation units whose source or target are not in the expected language.
Near-duplicates
Removes translation units whose source and target are duplicates or near duplicates of other TU.
Inconsistencies
Removes translation units containing translation inconsistencies in source or target.
Sensitive data
Anonymization. Removes translation units that contain data similar to personal data.
Alignment check
Alignment check by calculating mutual translation probability score based on parallel corpus data. Detects noisy sentence pairs in a parallel corpus.
Ready to get started?
Small business
Best for: high volume, reccuring needs
$180/month
2000 segments included
$2 over the limit, per thousand segments
Large Volume
Best for: medium volume, occasional need
$800/month
30,000 segments included
$0,25 over the limit, per thousand segments
IMPROVE YOUR MT QUALITY
Get the most out of your machine translation