
OpenAI has recently expanded its offerings by making GPT-4o available for fine-tuning! Just in time for us to explore the custom translation opportunities provided by this advanced solution on the market.
This new capability allows users to tailor GPT-4o to meet specific localization requirements, ensuring that the translation output adheres to pre-defined terminologies, translation memories, and style guides. Please note that after the training is complete, your GPT-4o preset will become solely a specialized translation tool unable to perform other functions, previously accessible, like searching for information or maintaining a conversation.
When utilizing generative AI for translation, the results can vary, but comprehensive fine-tuning can bring GPT-4o to best level of performance currently available for automated translation. This process is also cost-effective compared to other major translation services.
| Service | Cost Details |
| OpenAI GPT-4o | Average fine-tuning cost: $50 |
| Google Translate | $45 per hour, up to $300 for 6 hours |
| Microsoft Translator | $10 per million source + target characters, max $300 per training |
Fine-tuning can be performed through OpenAI’s user interface or through API calls. This upcoming guide will detail both methods. Previously GPT-4 and GPT-4o models were accessible through an experimental access program only. We are excited to release an update guide for all of our users. Please note that both models are available through our platform or through CAT-tool integrations.
- Create the Dataset
- Uploading a File to Open AI
- Creating a Fine-Tuning Job
- Translation Output after Training
1. Create the Dataset
Google Translate and Microsoft Translator use glossaries in TBX and translation memories in TMX. But OpenAI requirements suggest their models are fine-tuned using JSON files. So to start with, convert TMX and TBX into JSON. Here is a JSON structure example for your reference:
[
{ // First JSON object
“messages”: [
{
“role”: “system”,
“content”: “system text 1”
},
{
“role”: “user”,
“content”: “user text 1”
},
{
“role”: “assistant”,
“content”: “assistant text 1”
}
]
},
{ // Second JSON object
“messages”: [
{
“role”: “system”,
“content”: “system text 2”
},
{
“role”: “user”,
“content”: “user text 2”
},
{
“role”: “assistant”,
“content”: “assistant text 2”
}
]
},
{ // Third JSON object (and so on…)
“messages”: [
{
“role”: “system”,
“content”: “system text 3”
},
{
“role”: “user”,
“content”: “user text 3”
},
{
“role”: “assistant”,
“content”: “assistant text 3”
}
]
}
]
At Custom.MT, we convert TMX files into JSON using a custom Python script, which can be developed by a coder, or you can request GPT-4o to write such a converter for you with a prompt that includes the example JSON structure above along with a snippet of your translation memory. Here is an example of what our converter looks like:
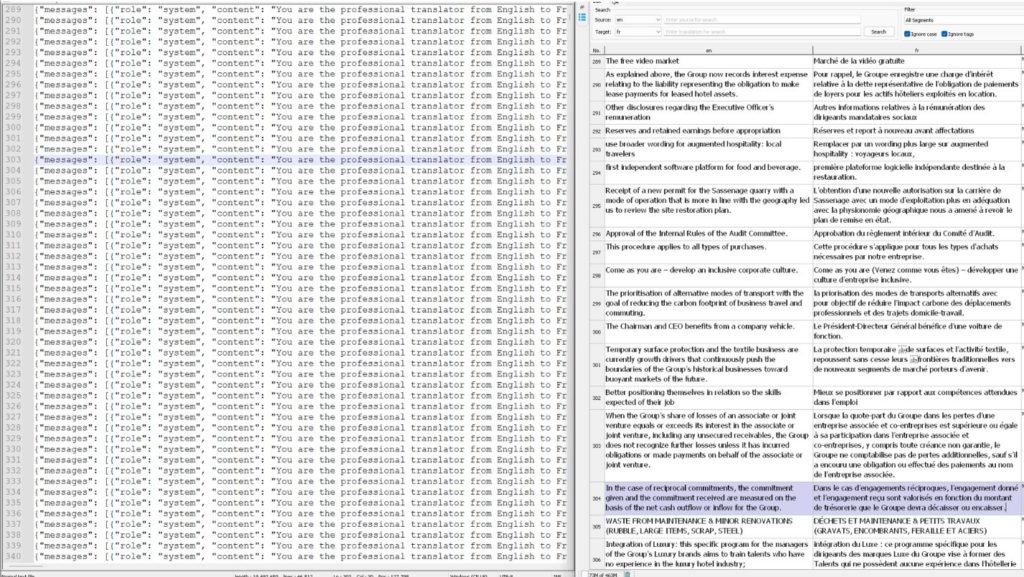
When fine-tuning language models like OpenAI’s LLMs, it is crucial to use only the highest quality data. A small number of excellent examples can lead to better results than a large quantity of mediocre data. To achieve higher quality of the dataset, we employ a proprietary tool named Custom.MT TMX Cleaner that maintains data integrity by removing any data that is outdated, inconsistent, or poses a risk.
2. Uploading a File to Open AI
After preparing the dataset, you may proceed to upload it to OpenAI. As stated before, this can be achieved through either Open AI UI or the API.
To upload the dataset via the UI, go to the OpenAPI account > Dashboard. On the left menu, click Storage > Upload.
To upload programmatically, we recommend using a Python script. Programmatic uploads will enable you to launch fine-tuning jobs without manual operations; for example, if you would like your TMS to automatically fine-tune regularly. Here is an example upload script in Python:
from openai import OpenAI
client = OpenAI(api_key=’ your key ‘)
client.files.create(
file=open(“en-fr-gpt.jsonl”, “rb”),
purpose=”fine-tune”
)
3. Creating a Fine-Tuning Job
The controls, once again, are available via the user interface or the API.
Using OpenAI UI, click at the right menu: Fine-Tuning > Create. Choose the currently available model and your JSON file.
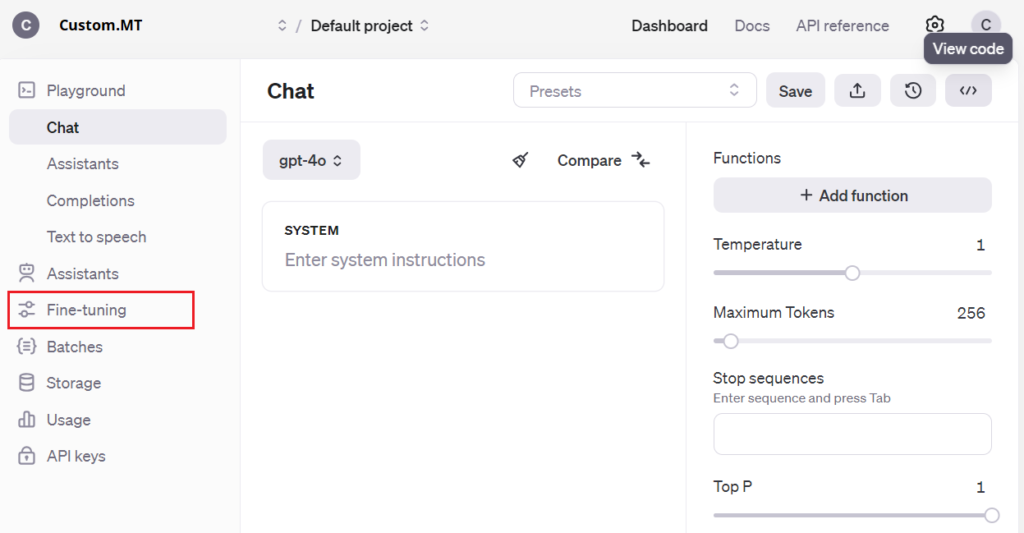
From the left-hand menu, pick Fine-Tuning, then click Create on the right side of the screen. Choose your model from the pool of currently available for fine-tuning, and your JSON file.
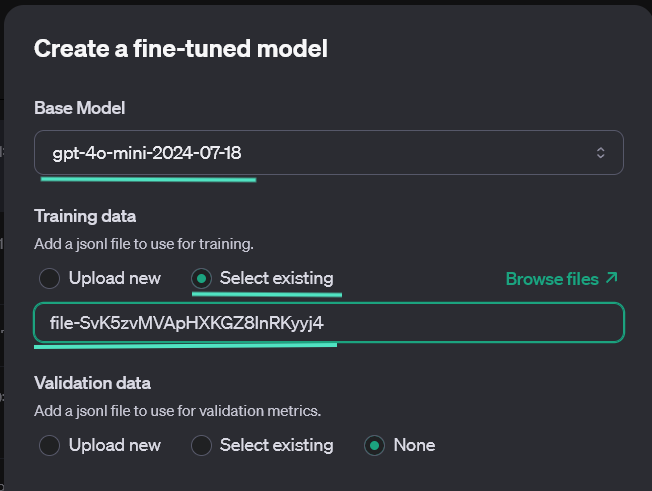
JsonID can be found after you click on the file you uploaded in the Storage,

Here is how to create a fine-tuning job in Python:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file=”file-abc123″,
model=”gpt-4-mini”
)
The training time depends on the size of the dataset, typically we observe 1-1.5 hour training time for fine-tuning jobs with smaller and cleaner translation memories with approximately 1 million words.

Once the fine-tuning is complete, a green check mark will appear in the UI.
4. Translation Output after Training
Fine-tuned translation often shows greater accuracy and context alignment, using terminology that is more appropriate for the given context:
| Original Sentence | GPT Stock Translation | GPT Fine-Tuned Translation |
| Can you help me with the recipes in Heather’s kitchen? | Pouvez-vous m’aider avec les recettes dans la cuisine de Heather? | Pouvez-vous m’aider avec les recettes dans Heather’s kitchen? |
| Veuillez connecter l’appareil Bluetooth à l’ordinateur. | Please connect the Bluetooth device to the computer. | Please link the Bluetooth device to the laptop. |
| J’ai besoin de configurer le nouveau routeur Wi-Fi. | I need to set up the new Wi-Fi router. | I need to configure the new Wi-Fi router. |
Are you considering leveraging generative AI for translation within your organization but unsure how to begin? Schedule a free consultation at https://custom.mt/book-a-call/ to receive personalized roadmap that best fits your guidelines and preferences.

Comments are closed.