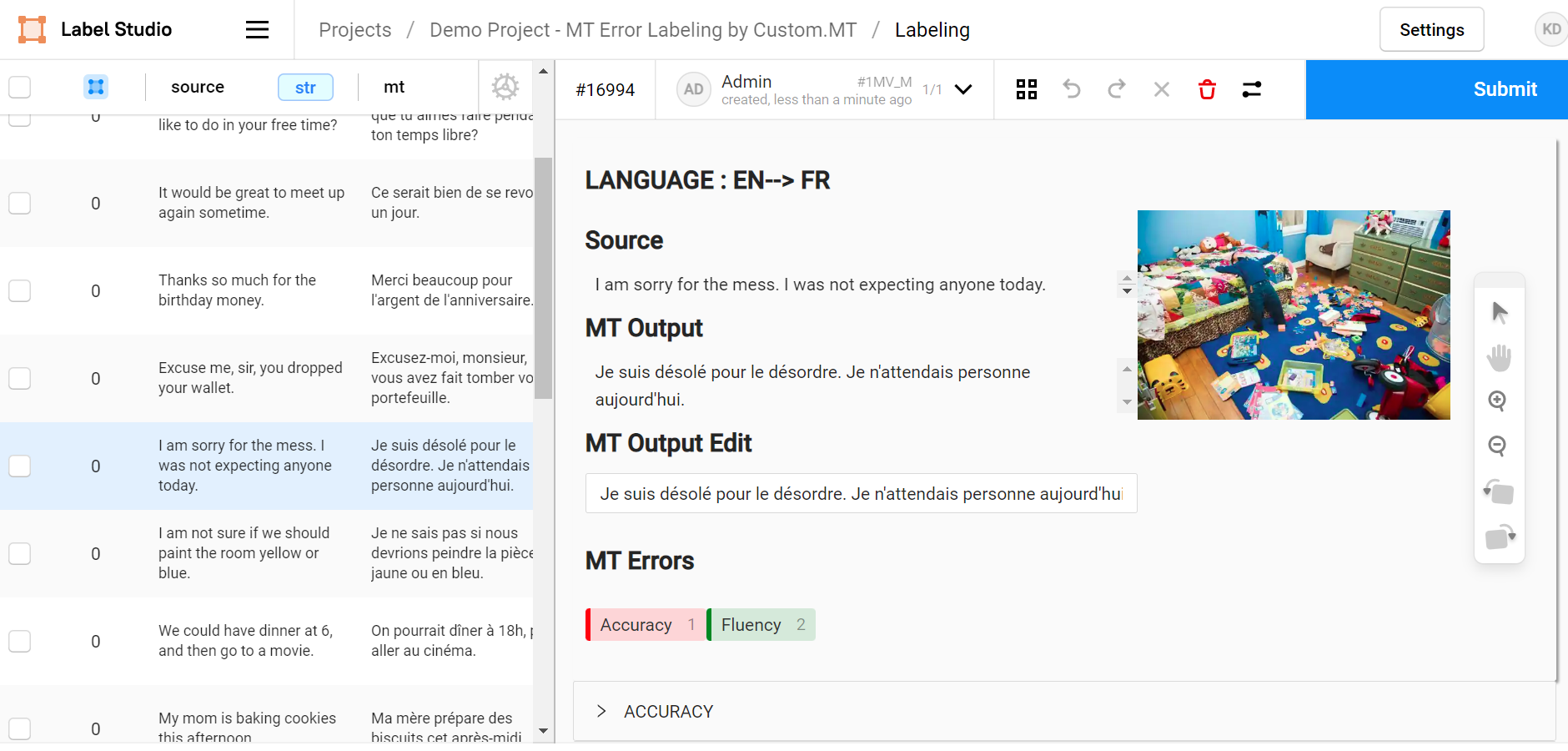
Running professional human evaluations of machine translation requires detailed methodology and software tools to streamline the process. The most detailed approach to evaluation today is to label errors and assign weights to critical issues using a variation of DQF/MQM ontology. In this article, we outline Custom.MT’s journey to selecting and implementing a tool for human evaluation of MT. It will be useful for all teams that face a similar challenge.
Measuring machine translation (MT) quality by the number of errors per 1000 words and assigning weights to critical errors focuses engineers on important issues. Neural MT can produce fluent, human-like output but it often hides catastrophic errors.
Here is one example from our work: a machine translation engine produced a smooth translation where it changed “50 mV” to “50 V”. Only one symbol was wrong, but that spelled a 1000x increase in voltage. Automated metrics BLEU, WER, chrF, and TER consider this translation “almost perfect”. In reality, should someone use the translation and apply a 1000x increase in voltage, it could potentially destroy electronic equipment.
To address this type of issue, error classification metrics were developed by Dr. Arle Lommel in 2013 as MQM (Multidimensional Quality Metrics) and continued in 2015 by TAUS as DQF (Dynamic Quality Framework). The metric has been adopted by teams at Google Translate and Microsoft Translator with some simplification and different weight formulas.
Here is our take on the error typology.
| Error type | Weight | Description |
| Accuracy | x3 | mistranslation, missing translation, omission, under-, and over-translation, addition |
| Language fluency | x2 | spelling, grammar, punctuation, encoding, inconsistency, capitalization |
| Locale convention | x2 | formats of addresses, dates, currencies, and telephone numbers are not correct |
| Style | x1 | company style, awkward, unidiomatic |
| Terminology | x2 | inconsistent with termbase, inconsistent use of terminology |
| Translated DNT | x2 | do not translate |
| Spaсing | x1 | double spaces, trailing punctuation |
| Severity Level | Weight | Description |
| Critical Errors | x5 | Carry health, safety, legal or financial implications, violate geopolitical usage guidelines, damage the company’s reputation, or could be seen as offensive statements. |
| Major Errors | x3 | May confuse or mislead the user or hinder proper use of the product/service due to significant changes in meaning or because errors appear in a visible or important part of the content. |
| Minor Errors | x1 | These don’t lead to a loss of meaning and wouldn’t confuse or mislead the user. They might make the content less appealing. |
Starting with Spreadsheets for DQF/MQM
We began with Excel & Google Docs. At the start of our error classification tasks at Custom.MT, we asked linguists to review machine translation in spreadsheets. Our initial setup was simple, as we used dropdown lists to allow for the selection of error types and severities based on the MQM framework.
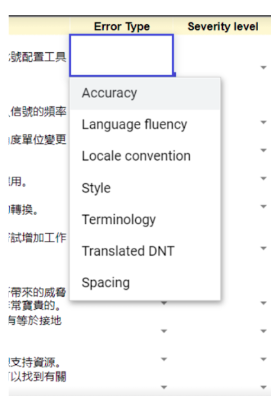
An additional page provided instructions to linguists, and we aimed to keep it as concise as possible. Within weeks of deploying this approach, we hit several problems.
- Working in Excel was boring, and linguists got burned out, especially when comparing outputs from several engines for 5-8 hours a day;
- Distributing files to linguists was cumbersome for the PMs, especially with 5-10 language evaluations using 3 linguists per language;
- There were risks of introducing errors to the source;
- We didn’t track time in Excel, and had no way to measure cognitive effort;
- Attaching images for visual references in Excel was cumbersome.
Moreover, linguists without DQF/MQM training tended to report errors in different ways, what was Stylistic for one person turned out Accuracy for another evaluator. As a company specializing in machine translation, we wanted to professionalize this work and started working on a tool to streamline error classification.
MT Quality Evaluation in Phrase TMS
First, we turned to CAT tools such as Phrase (Memsource) and Smartcat, because linguists often work there and they are very familiar with the UI. Phrase, for example, has an LQA feature that is built for this purpose, a feature that has been adopted by Translators without Borders.
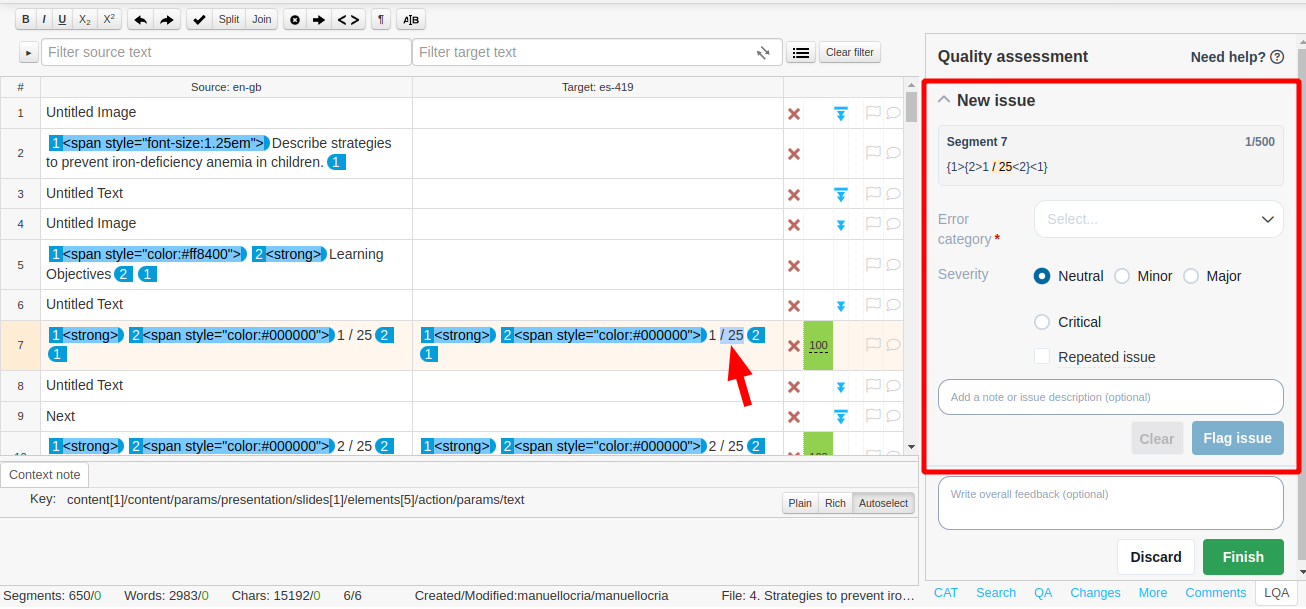
However, this tool did not stick internally, because couldn’t customize it freely. We wanted to be able to quickly tweak the error typology, track time, highlight parts of the sentences, and provide instructions.

KEOPS
In a subsequent phase, our team turned to KEOPS, developed by our partner Prompsit Language Engineering in Spain. KEOPS is easy to use, it’s free and it’s a specialist MT error annotation tool.
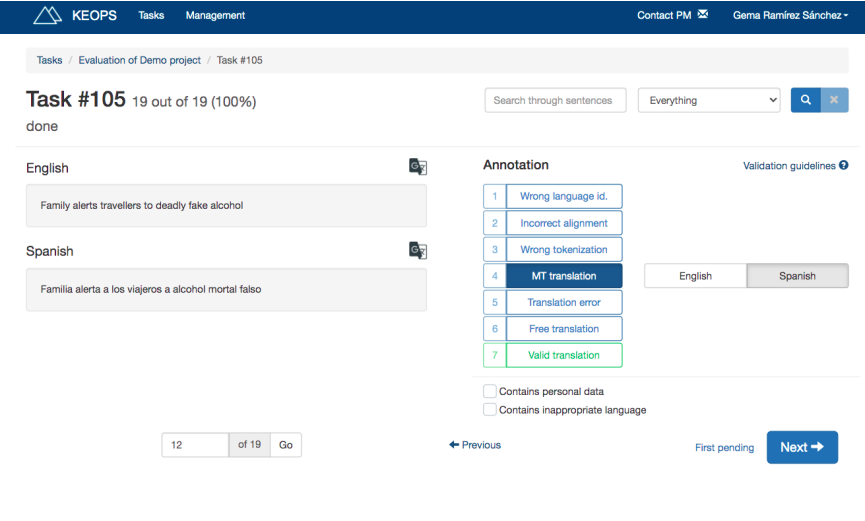
We’ve experimented with two projects, but decided to move on as well, as KEOPS did not fit the following requirements:
- The error categories are fixed and cannot be customized by the PM;
- The application doesn’t have the option to edit segments with better translations;
- The linguist cannot highlight errors inside the sentence;
- We didn’t find a way to evaluate multiple parameters like Adequacy, Fluency, and Paraphrase in a single project.
As a UI, the program is absolutely easy and intuitive to use, but from the PM’s side, the error evaluation typologies are pre-established and you cannot customize the platform as you need it. This’s why we kept looking for a more versatile platform.
Evaluating Machine Translation Quality in Label Studio
Our final choice was Label Studio, an open-source data labeling platform maintained by Heartex in the same way as WordPress is maintained by Automattic. Label Studio is free to start using, to customize, and it is very flexible due to scripting options. The ability to tweak on the fly and adapt to various projects, changing details as needed was the key decision factor for us. We hosted Label Studio in a dedicated AWS instance and started tweaking it around from project to project. In our first iteration, machine translation error labeling in Label Studio looked very much like Excel, but it quickly evolved to be more detailed and visual.
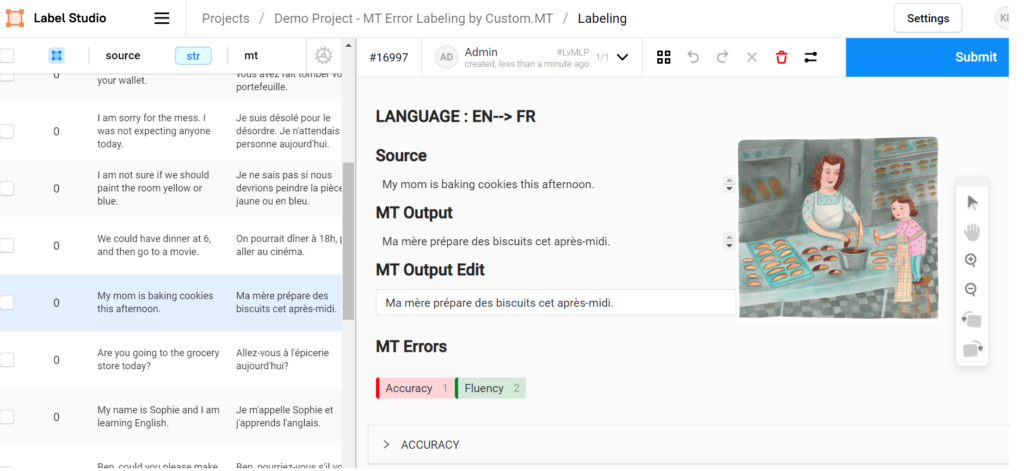
As of the time of writing this article, the Label Studio deployment for our error classification tasks has the following features:
- A clear and intuitive user interface
- The ability to easily modify the error typology
- The option to include a video to brief linguists
- A login system and basic user management with no limit on the number of users
- The ability for linguists to highlight errors in the sentence and add multiple highlights per segment
- Tracking of edit time for each segment
- Real-time progress tracking for project managers
By building competency with Label Studio, we were able to set up annotation projects for different types of data, both text and image + text.
Conclusion
Detailed data annotation is a growing field, driven by the need for specialist AI models. Many tools have been developed over the last 2 years by the leading annotation providers, including Toloka, Scale AI, Hive Data, and so on, but they are not focused on machine translation and are not familiar to linguists. On the other hand, translation tools that are familiar to linguists, lack the feature set and the flexibility required to quickly deploy machine translation evaluation setups.
We believe that by taking an open-source software and iteratively improving it for machine translation, we’ve achieved one of the best setups possible and that our experience will be useful for other teams evaluating MT.
Frequently Asked Questions
The most reliable approach is to use human error annotation based on MQM/DQF frameworks. This allows evaluators to categorize errors, assign severity weights, and detect issues that automated metrics like BLEU or TER cannot catch.
Automated machine translation evaluation metrics compare MT output to a reference translation. BLEU measures word-level overlaps, WER tracks word-level edits, chrF analyzes character-level similarity, and TER (Translation Edit Rate) calculates how many edits are needed to fix a translation. These metrics are fast and useful for benchmarking, but they can miss critical meaning errors, especially in fluent neural MT output.
MQM (Multidimensional Quality Metrics) and DQF (Dynamic Quality Framework) are structured human evaluation systems that classify errors (Accuracy, Fluency, Terminology, etc.) and assign severity weights. Unlike automated metrics, MQM/DQF detect subtle but high-impact errors—such as wrong numbers or mistranslated medical terms—that automated scores often overlook. They are the preferred method for accurate, risk-aware MT quality assessment.
MQM/DQF is language-agnostic and adaptable to any domain, making it suitable for multilingual programs and enterprise translation workflows.
Effective tools should support customizable error typologies, segment highlighting, time tracking, linguist guidance, and scalable user management while maintaining a clean and intuitive user interface
Custom.MT tailors MQM/DQF error categories to match each client’s terminology, compliance needs, and domain requirements. This ensures that linguists evaluate MT output using criteria aligned with real business risks and quality goals.
If you want to compare human annotation workflows with GenAI quality scoring, check out our detailed article on Measuring Language Quality with GenAI. Learn how AI can streamline MT evaluation and improve consistency across projects.
