
Author: Konstantin Dranch
Subtitlers are looking to adopt customized machine translation, but video localization systems are not ready for it yet. Here is what they could do to expedite up the process.
Since Google introduced AutoML translation and Microsoft created Custom Translator, text translation management systems (TMS) have developed excellent support for trainable machine translation.
Translation tools such as Trados, memoQ, Memsource, Smartling, Crowdin, Smartcat, and Wordbee all have multiple integrations with machine translation (MT), including MT that can be trained. The TMS also developed tools to measure human effort editing machine output.
The ability to train and use the trained models spawned an ecosystem of professional MT implementation specialists, tools, datasets & model marketplaces, and best practices.
In contrast, in the world of subtitling, the support for customizable engines does not exist yet. Popular captioning and subtitling tools such as Ooona, Limecraft, Syncwords, Dotsub, Yella Umbrella, VoiceQ still don’t offer the ability to use trained models.
SubtitleNext was one of the first tools for video localization to introduce custom machine translation models via Microsoft Custom Translator. Most others integrate with Apptek’s MT which can be trained but does not yet offer a self-service training console to support trainers.
I hope for this to change in the next 3-6 months.
What Subtitling Tools Need to Do
- Integrate more MT brands and specifically customizable MT systems
Ooona, Limecraft, Syncwords, SubtitleNext, DotSub, Yella Umbrella, VoiceQ, and others should add integrations with customizable machine translation, at least with popular brands.
- Big IT: Google, Microsoft, Amazon ACT, Yandex
- Dedicated EU vendors: ModernMT, Globalese, Kantan, Systran, PangeaMT
- Dedicated Asian vendors: Niutrans, Cloud Translation, Mirai and Rozetta, Tencent
There are more than 100 machine translation providers on the market, having integrations with at least 7-10 of them either directly or via middleware would be a crucial first step for your video localization product.
2. Support for full-text subtitle translation instead of per-line
Translating subtitles is different from translating normal text due to line breaks. Subtitles have a limitation of two lines max and a certain number of characters, for example, 37 characters with the BBC.
Sending 37 characters to MT without context results in poor quality. It’s like translating dialogue without knowing what the dialogue is about. To fix it, professional subtitling tools instead send the full text, then re-segment the translation again and put it in the right place in the video.
3. Effort analysis
As AI gets better, it reduces the amount of manual work. Captioning a video takes 5-10 hours per hour of source manually, and only 2-4 hours with the help of speech recognition and automatic time coding. The same with translating subtitles: machine translation helps to the extent of its accuracy.
To measure the impact of speech recognition and machine translation, subtitling tools need to add effort measuring functionality with the following metrics:
- Edit distance in characters, words, and lines
- Time tracking functionality
This will allow subtitling specialists to decide which ASR and MT model is better for them, and also to quantify savings from using them. Once the industry can establish the correlation between AI performance and the price per minute of video, there will be a clear financial incentive to build better AI.
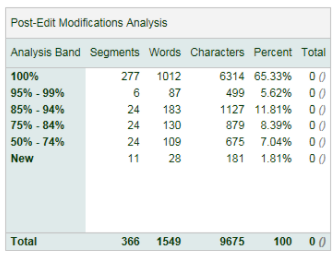
Subtitling software can simply copy the functionalities of text translation systems. Or, invest resources into doing something more glamourous. Perhaps, create a neural network that will tell the professional users automatically how much they saved with AI.
4. MT Training controls from within subtitling tools
Microsoft and some other MT brands already offer APIs for model training. Training then can happen without logging into the MT console. It could be a button in the subtitling tool.
With some coding shenanigans, subtitling software providers can allow their users to train MT without learning the consoles for training, configuring tokens, and exchanging JSON scripts. This would make training available to everyone, from engineers to linguists.
Subtitling studios and subtitles will be able to create models for each domain they specialize in and have enough training data. News, Football, or Star Wars Universe could all be examples of domain models trained and managed from within a subtitling tool.
Conclusion
There is more need than ever for subtitling with the TV series explosion on streaming platforms, the increase in scripted television programs, eLearning, and the general rise of video as the means of communication in business.
To get more videos subtitled professionally, the service needs to be more affordable on a per-minute basis. One way to achieve it is to add better support for AI in the tools. And this is something very practical to accomplish for subtitling software developers.

Konstantin Dranch is the Co-Founder of Custom.MT. He is a localization expert with a background in journalism, market research and technology and has worked in the localization industry for several years.

Comments are closed.