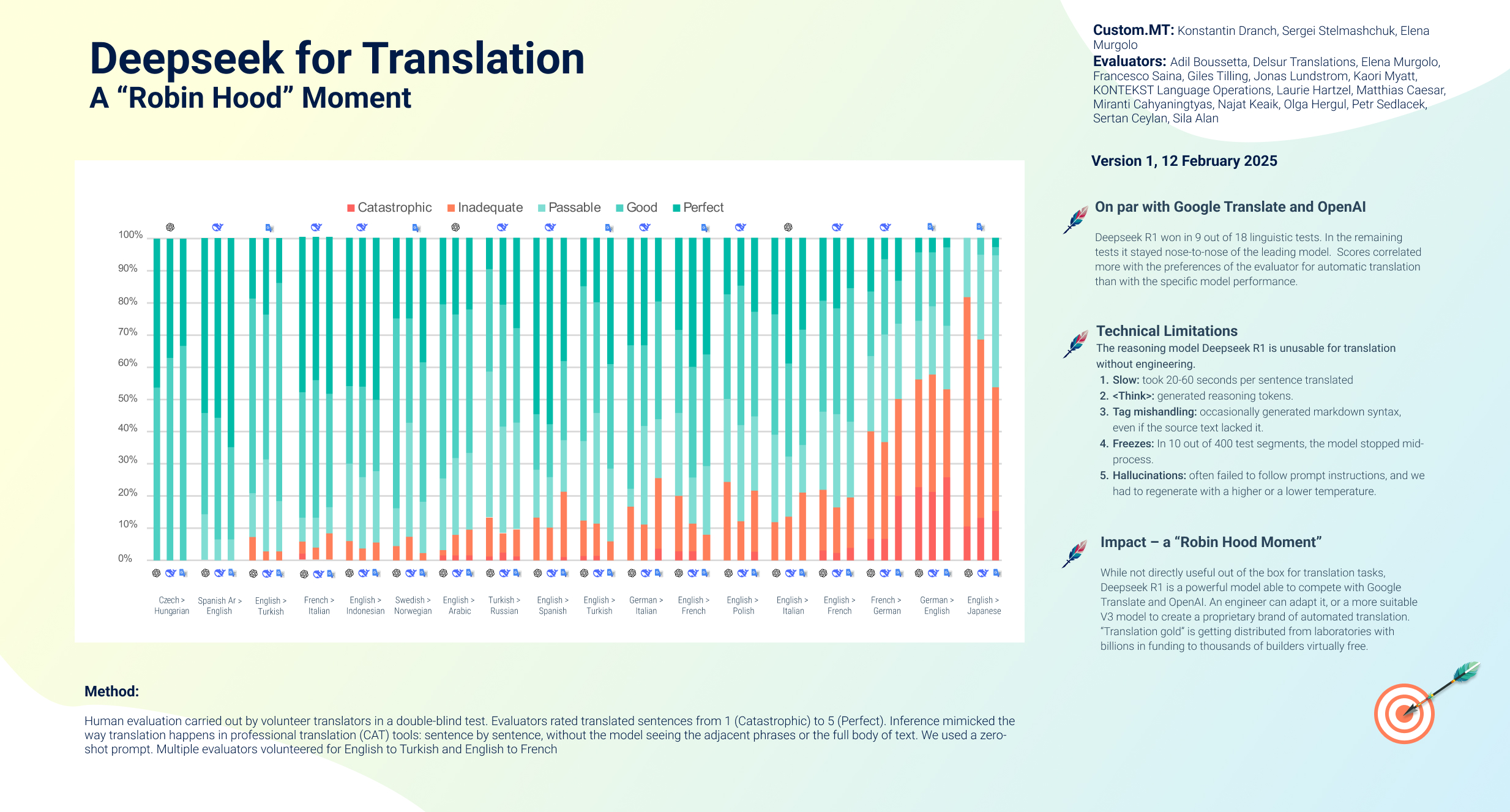
Part 1 of the evaluation with scores
{kind=link}
Сommunity’s evaluation of Deepseek’s translation accuracy is complete.
- Deepseek won in 9 out of 18 linguistic tests. In six out of seven remaining tests it stayed within 5% of the leading model.
- A clean human test. Volunteer professional linguists rated the translations. They had no information about which output came from which model. It was a double blind test without bias toward any particular brand.
- Support for low-resourced language combinations. The evaluation included language combinations without English: Czech to Hungarian, Swedish to Norwegian, French to Italian, Turkish to Russian, and French to German. Subject matter areas ranged from marketing websites to legal and medical texts. Deepseek performed well in almost all of them. It fell short of the leader only in one test – with English to Japanese. In this particular test, however, all models received poor ratings.
Conclusion: Deepseek is a top-notch translation powerhouse racing nose-to-nose with the market leaders. The differences were small, and the ratings depended more on personal preferences of evaluators towards computer-generated translation, rather than model performance.
And it will get better
We structured this first evaluation to mimic the way translations happen in professional translation (CAT) tools: sentence by sentence, without the model getting the adjacent phrases or the full body of text. This approach penalizes large language models that thrive in scenarios with context. As we expand benchmarking to full text, we will certainly see improved translation performance from LLMs.
Moreover, in the first evaluation we used a simple zero-shot prompt not priming the model to specific subject matter areas or styles. With a little bit of tweaking, the linguists may get the outputs more in line with their preferences.
With a few tweaks to the process, we can significantly improve LLM performance.
Technical Limitations
Yet, in its present form, Deepseek R1 is unusable for professional translation.
- Slow: using Deepseek’s R1 hosted in the Western datacenter by Together.AI, we had to wait 20-60 seconds per sentence translated. In contrast, neural machine translation requires 1-2 seconds per sentence.
- Artifacts: it generated <think> tokens, especially when presented with 5+ sentences at once. “Hmm, the user asked me to translate this, let’s go word by word..”. Our engineers had to remove them manually before sending translations to linguists.
- Unwanted tag handling: Deepseek occasionally generated markdown syntax, even when the source text lacked it.
- Instruction Non-Compliance: Deepseek often failed to follow prompt instructions, and we had to regenerate with a higher or a lower temperature.
- Incomplete Translations: In 10 out of 400 test segments, the model stopped generating inference mid-process, failing to provide a translation. We increased temperature and relaunched translations which resolved this issue.
- High entry costs for on-prem: a full-sized Deepseek model requires a minimum of 6x A100 Nvidia GPUs to run, which translates to $52,500 in GPU rental costs per year. For faster speed and larger volumes, engineers will ask for 8x H100 units, at the rent cost of more than $100,000 per year.
In short, the largest model Deepseek R1 is slow and unstable out of the box, and needs to be reduced in size (distilled), fine-tuned for translation and integrated into translation tools with protocols in place to relaunch stuck translations. We’re sure to see many AI teams around the world doing exactly that in the near future.
A Robin Hood moment
Unlike OpenAI and Claude, Deepseek’s models are open source, and AI engineers are free to reuse and distill them into their own creations and recipes. With an injection of proprietary data, such as a collection of high quality translations, a derivative model will become proprietary, and the translation company or the enterprise team that trained it may use it for business, skipping commercial products such as DeepL or Google Translate.
In November 2024, Tower-2 model by Ricardo Rei and André Martins from Unbabel outperformed popular commercial products such as Google Translate, DeepL, and Microsoft Translator in 9 out of 11 language tasks at WMT24 competition. According to Tower’s paper, it was made by pre-training Meta’s Llama-2, finetuned on high-quality machine translation instructions. With Deepseek performing better than Llama-2 and others in translation tasks, model makers can switch from Llama and get the leading performance with less investment and know-how. There is no guarantee a novice engineer may get to the level of reliability tried-and-tested commercial products offer, but with a stronger foundational model to start with the path to join the race has just got shorter.
A hundred viable alternatives to Google Translate, ChatGPT, DeepL and other popular translation products may spring up. And perhaps one day soon, quality will no longer be the main differentiator between models.
And the trickiest part? Should the suspicions that Deepseek distilled closed-source OpenAI models to make their own product be proven accurate, it will be already too late to trace and recall all derivatives from the market. It’s not that OpenAI or other model makers paid for data in the first place. That is why most companies don’t say what datasets they really used, or they explicitly mention they are built with synthetic data (Microsoft’s Phi-4 for example).
The “gold” of translation AI is already out from the research labs of the rich with billions of dollars in investment and it is getting distributed to thousands of developers. And there is no Sheriff of Nottingham in sight to get it back.
It’s a Robin Hood-like moment in language AI.
| Test | Model | Catastrophic | Inadequate | Passable | Good | Perfect |
| EN>TR | GPT 4o | 1.37% | 10.96% | 24.66% | 47.95% | 15.07% |
| Sila Alan | Deepseek R1 | 1.37% | 9.59% | 32.88% | 36.99% | 19.18% |
| Google Translate | 0.00% | 8.22% | 31.51% | 45.21% | 15.07% | |
| EN>PL | GPT 4o | 0.00% | 24.32% | 25.68% | 32.43% | 17.57% |
| Kontext | Deepseek R1 | 0.00% | 12.16% | 29.73% | 43.24% | 14.86% |
| Google Translate | 2.70% | 18.92% | 22.97% | 32.43% | 22.97% | |
| DE>EN | GPT 4o | 22.73% | 33.33% | 18.18% | 21.21% | 4.55% |
| Giles Tilling | Deepseek R1 | 21.21% | 36.36% | 21.21% | 16.67% | 4.55% |
| Google Translate | 25.76% | 27.27% | 19.70% | 24.24% | 3.03% | |
| FR>IT | GPT 4o | 1.85% | 3.70% | 7.41% | 38.89% | 48.15% |
| Francesco Saina | Deepseek R1 | 0.00% | 3.70% | 9.26% | 42.59% | 44.44% |
| Google Translate | 0.00% | 5.56% | 5.56% | 24.07% | 64.81% | |
| EN>ID | GPT 4o | 0.00% | 6.00% | 24.00% | 24.00% | 46.00% |
| Miranti Cahyaningtyas | Deepseek R1 | 0.00% | 4.00% | 22.00% | 28.00% | 46.00% |
| Google Translate | 0.00% | 6.00% | 22.00% | 22.00% | 50.00% | |
| SV>NO | GPT 4o | 0.00% | 4.41% | 11.76% | 58.82% | 25.00% |
| Jonas Lundstrom | Deepseek R1 | 0.00% | 7.35% | 35.29% | 32.35% | 25.00% |
| Google Translate | 0.00% | 2.94% | 20.59% | 55.88% | 20.59% | |
| EN>JA | GPT 4o | 10.53% | 71.05% | 18.42% | 0.00% | 0.00% |
| Kaori Myatt | Deepseek R1 | 13.16% | 55.26% | 26.32% | 5.26% | 0.00% |
| Google Translate | 15.79% | 39.47% | 42.11% | 2.63% | 0.00% | |
| CZ>HU | GPT 4o | 0.00% | 0.00% | 0.00% | 53.70% | 46.30% |
| Petr Sedlacek | Deepseek R1 | 0.00% | 0.00% | 0.00% | 62.96% | 37.04% |
| Google Translate | 0.00% | 0.00% | 0.00% | 66.67% | 33.33% | |
| EN>FR | GPT 4o | 2.86% | 17.14% | 25.71% | 25.71% | 28.57% |
| Adil Boussetta | Deepseek R1 | 2.86% | 8.57% | 14.29% | 34.29% | 40.00% |
| Google Translate | 0.00% | 8.57% | 22.86% | 37.14% | 31.43% | |
| EN>ES | GPT 4o | 0.00% | 13.28% | 14.84% | 17.19% | 54.69% |
| Laurie Hartzel | Deepseek R1 | 0.00% | 10.16% | 15.63% | 16.41% | 57.81% |
| Google Translate | 0.78% | 14.84% | 11.72% | 17.97% | 54.69% | |
| FR>DE | GPT 4o | 6.67% | 33.33% | 23.33% | 20.00% | 16.67% |
| Matthias Caesar | Deepseek R1 | 6.67% | 30.00% | 33.33% | 23.33% | 6.67% |
| Google Translate | 20.00% | 30.00% | 23.33% | 13.33% | 13.33% | |
| EN>AR | GPT 4o | 1.59% | 1.59% | 22.22% | 53.97% | 20.63% |
| Najat Keaik | Deepseek R1 | 1.59% | 6.35% | 23.81% | 44.44% | 23.81% |
| Google Translate | 1.59% | 7.94% | 23.81% | 44.44% | 22.22% | |
| TR>RU | GPT 4o | 1.22% | 12.20% | 45.12% | 31.71% | 9.76% |
| Olga Hergul | Deepseek R1 | 2.44% | 6.10% | 32.93% | 37.80% | 20.73% |
| Google Translate | 1.22% | 8.54% | 32.93% | 29.27% | 28.05% | |
| DE>IT | GPT 4o | 0.00% | 16.67% | 5.56% | 44.44% | 33.33% |
| Elena Murgolo | Deepseek R1 | 0.00% | 11.11% | 30.56% | 25.00% | 33.33% |
| Google Translate | 2.78% | 16.67% | 13.89% | 27.78% | 38.89% | |
| EN>IT | GPT 4o | 0.00% | 11.86% | 27.12% | 37.29% | 23.73% |
| Elena Murgolo | Deepseek R1 | 0.00% | 13.56% | 18.64% | 28.81% | 38.98% |
| Google Translate | 0.00% | 16.95% | 11.86% | 28.81% | 42.37% | |
| EN>FR | GPT 4o | 3.13% | 18.75% | 24.22% | 34.38% | 19.53% |
| Myriam Bocquillon | Deepseek R1 | 2.34% | 14.06% | 28.91% | 32.81% | 21.88% |
| Google Translate | 3.91% | 15.63% | 23.44% | 41.41% | 15.63% | |
| EN>ES(LA) | GPT 4o | 0.00% | 0.00% | 14.38% | 32.19% | 53.42% |
| Delsur | Deepseek R1 | 0.00% | 0.00% | 6.16% | 38.36% | 55.48% |
| Google Translate | 0.00% | 0.00% | 6.16% | 29.45% | 64.38% | |
| EN>TR | GPT 4o | 0.00% | 7.41% | 14.63% | 59.26% | 18.52% |
| Sertan Ceylan | Deepseek R1 R1 | 0.00% | 3.70% | 29.63% | 44.44% | 22.22% |
| Google Translate | 0.00% | 3.70% | 14.81% | 66.67% | 14.81% |
Thank you for contributing ideas and counter-arguements:
- Gema Ramirez-Sanchez (Promptsit, EuroLLM)
- Ricardo Rei and Joao Graca (Unbabel)
- Marco Trombetti (Translated)
Opinions expressed are our own.
