Fine-tuning GPT-3.5 for translation involves converting TMX/TBX files into JSONL, uploading training data to OpenAI, and launching a fine-tuning job via the UI or API. This process customizes terminology, improves accuracy, and brings performance closer to GPT-4o for translation tasks.
OpenAI platform offers its users an opportunity to fine-tune GPT-3.5. For localization needs, one can train the AI to generate translation output with specific terminology, translation memory, and style guides. After the training, the model will not be able to generate dialogue-like answers anymore and will become a tool only for translation.
When you train Gen AI for translation the impact is somewhat less predictable than it is with machine translation. However, enough fine-tuning iterations will eventually get GPT-3.5 to an output quality level comparable to GPT-4o, with improved terminology compliance. The whole training generally costs $10-$100 which is significantly less than training Google Translate or Microsoft Custom Translator. For example:
- OpenAI GPT-3.5 average fine-tune – $50
- Google Translate fine-tune – $45 / hour, average 6 hours, $300 max
- Microsoft Translator fine-tune – $10 per million source + target characters of training data (max. $300/training)
There are two ways to run the fine-tune, via Open AI UI and API calls. In the following guide, we will cover both options. Please note that it is possible to fine-tune GPT-4 and GPT-4o in the experimental access program. The workflow is the same, and eligible users can request access in the fine-tuning interface when creating a new fine-tuning job.
Creating the Data Set for AI Training
Unlike Google Translate and Microsoft Translator, which use glossaries in TBX and translation memories in TMX, OpenAI’s models need to be fine-tuned with JSON files. So the first step is to convert TMX and TBX into JSON. Here is the example JSON structure that you can use:
[
{ // First JSON object
"messages": [
{
"role": "system",
"content": "system text 1"
},
{
"role": "user",
"content": "user text 1"
},
{
"role": "assistant",
"content": "assistant text 1"
}
]
},
{ // Second JSON object
"messages": [
{
"role": "system",
"content": "system text 2"
},
{
"role": "user",
"content": "user text 2"
},
{
"role": "assistant",
"content": "assistant text 2"
}
]
},
{ // Third JSON object (and so on...)
"messages": [
{
"role": "system",
"content": "system text 3"
},
{
"role": "user",
"content": "user text 3"
},
{
"role": "assistant",
"content": "assistant text 3"
}
]
}
]At Custom.MT, we convert TMX into JSON with a custom Python script, which can be developed by a coder, or you can ask GPT-4o to write such a converter for you with a prompt that shows the example JSON structure above and a snippet of your translation memory. Here is what our converter looks like:

Only add high-quality sentences to OpenAI. Fine-tuning LLMs doesn’t require a lot of examples, and it is better to delete all data that you consider old, inconsistent, and risky. We use a proprietary tool for that, called Custom.MT TMX Cleaner, but there are multiple open options on the market, such as Heartsome, TMop, Trados Cleanup, etc.
Uploading a Training File to Open AI
Once your dataset is ready, the only thing to do is to upload it to OpenAI. There are two ways how to do it, via Open AI UI, and via the API.
To upload the dataset via the API, go to the OpenAPI account > Dashboard. On the left menu, click Storage > Upload.

To upload programmatically, we recommend using a Python script. Programmatic uploads will enable you to launch fine-tuning jobs without manual operations, for example, if you’d like your TMS to automatically fine-tune regularly. Here is an example upload script in Python:
from openai import OpenAI
client = OpenAI(api_key="your-key")
client.files.create(
file=open("en-fr-gpt.jsonl", "rb"),
purpose="fine-tune"
)Creating a Fine-Tuning Job
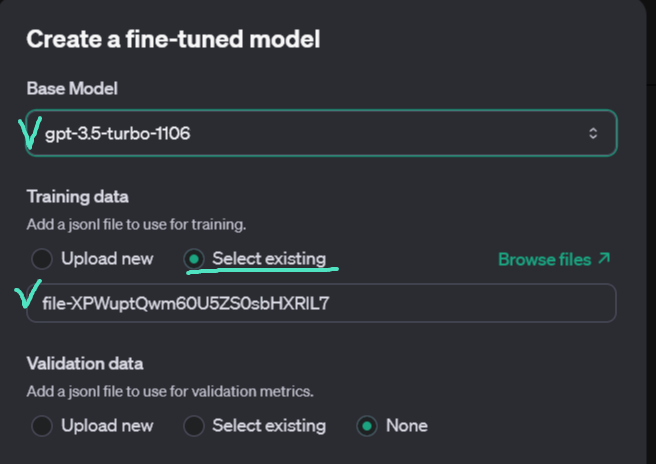
Again for this step, the controls are available via the user interface and the API. Here is how to create an OpenAI fine-tuning job via the UI:

From the left-hand menu, pick Fine-Tuning, then click Create on the right side of the screen. Chose your model from the pool of currently available for fine-tuning, and your JSON file.
JsonID can be found after clicking on the file you uploaded in the Storage,

Here is how to create a fine-tuning job in Python:
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo"
)Time to train the AI model depends on the size of the data set, typically we see 1-1.5 hour training time for fine-tuning jobs with smaller & cleaner translation memories with circa 1 million words in size.
Once the fine-tuning is complete, a green check mark will appear in the UI.

Translation Output after Training
Fine-tuned translation often shows greater accuracy and context alignment, using terminology that is more appropriate for the given context (e.g., “assistera à la conférence” vs. “participera à la conférence”). In the last example the translation remains unchanged since the first option complys with the requirements.
| English Sentence | GPT Stock Translation | GPT Fine-Tuned Translation |
| The free video market | Le marché vidéo libre | Marché de la vidéo gratuite |
| She will attend the conference next week. | Elle assistera à la conférence la semaine prochaine. | Elle participera à la conférence la semaine prochaine. |
| The company announced a new policy for employee benefits. | L’enterprise a annoncé une nouvelle politique pour les avantages des employés. | L’enterprise a annoncé une nouvelle politique pour les avantages des employés. |
The last sentence alligned with the requirments before training, so the output does not change.
Do you want to use GenAI for translation at your company but are not quite sure where to start? Book a free consultation with our AI and MT translation experts to quickly gain a comprehensive understanding of how AI can best assist you: https://custom.mt/book-a-call/
Frequently Asked Questions
GPT fine-tuning is the process of training a GPT model, such as GPT-3.5 or GPT-4, on your own bilingual data, terminology, or translation memory to produce more accurate and consistent translations. For localization teams, fine-tuning improves terminology compliance, style consistency, and domain accuracy while keeping training costs relatively low compared to traditional MT engine customization.
To fine-tune GPT for translation, you prepare a training dataset in JSONL format (converted from TMX/TBX or bilingual files), upload it to OpenAI, and run a fine-tuning job via the UI or API. During training, the model learns preferred terminology, phrasing, and style. After fine-tuning, the GPT model behaves like a dedicated translation engine rather than a conversational AI.
GPT fine-tuning requires fewer examples than traditional MT customization.
Most teams achieve strong results with tens of thousands of clean, high-quality segments.
Removing outdated or inconsistent translations is essential, as noisy data reduces model quality.
Training GPT-3.5 for translation typically costs $10–$100, depending on dataset size.
In comparison:
Google Translate Custom → ~$300 for an average job
Microsoft Custom Translator → ~$300 per training
You can convert training data using:
– A custom Python script
– GPT-4o (prompt-based conversion)
– Custom.MT’s TMX Cleaner + JSON converter
– Other tools include Heartsome, TMop, or Trados Cleanup for preparing clean bilingual data.
Most fine-tuning jobs on translation memories of ~1M words finish in 1–1.5 hours.
Larger or noisier datasets will extend training time.
